SafeGen: Integrating Privacy and Fairness in Machine Learning
2025
·
Publication
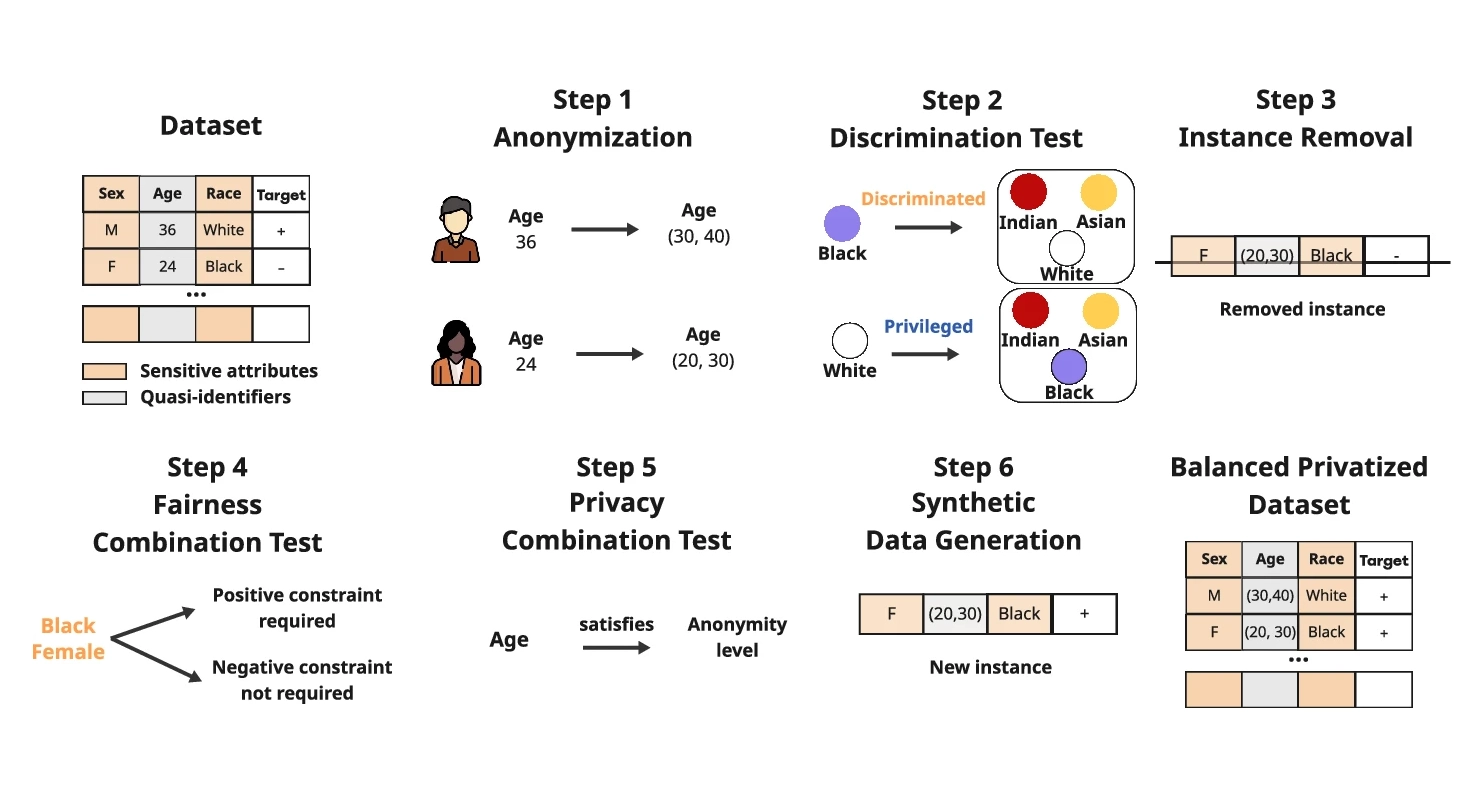
A new contribution from the XAI project published in Machine Learning (Springer) introduces SafeGen (Cinquini et al., 2025), a preprocessing method that simultaneously addresses privacy and fairness in tabular data.
The research demonstrates that separately optimizing privacy and fairness can lead to undesirable conflicts: privacy preservation techniques can worsen fairness and vice versa. SafeGen uses a genetic algorithm to generate synthetic data that maintains the necessary statistical properties while protecting sensitive attributes.
Experiments show that SafeGen achieves robust anonymization while preserving or improving dataset fairness, demonstrating the importance of integrated approaches when multiple ethical objectives must be met simultaneously.
References
2025
SafeGen: safeguarding privacy and fairness through a genetic method
Martina
Cinquini, Marta
Marchiori Manerba, Federico
Mazzoni, Francesca
Pratesi, and Riccardo
Guidotti
To ensure that Machine Learning systems produce unharmful outcomes, pursuing a joint optimization of performance and ethical profiles such as privacy and fairness is crucial. However, jointly optimizing these two ethical dimensions while maintaining predictive accuracy remains a fundamental challenge. Indeed, privacy-preserving techniques may worsen fairness and restrain the model’s ability to learn accurate statistical patterns, while data mitigation techniques may inadvertently compromise privacy. Aiming to bridge this gap, we propose safeGen, a preprocessing fairness enhancing and privacy-preserving method for tabular data. SafeGen employs synthetic data generation through a genetic algorithm to ensure that sensitive attributes are protected while maintaining the necessary statistical properties. We assess our method across multiple datasets, comparing it against state-of-the-art privacy-preserving and fairness approaches through a threefold evaluation: privacy preservation, fairness enhancement, and generated data plausibility. Through extensive experiments, we demonstrate that SafeGen consistently achieves strong anonymization while preserving or improving dataset fairness across several benchmarks. Additionally, through hybrid privacy-fairness constraints and the use of a genetic synthesizer, SafeGen ensures the plausibility of synthetic records while minimizing discrimination. Our findings demonstrate that modeling fairness and privacy within a unified generative method yields significantly better outcomes than addressing these constraints separately, reinforcing the importance of integrated approaches when multiple ethical objectives must be simultaneously satisfied.
@article{CMM2025,author={Cinquini, Martina and Marchiori Manerba, Marta and Mazzoni, Federico and Pratesi, Francesca and Guidotti, Riccardo},doi={10.1007/s10994-025-06835-9},issn={1573-0565},journal={Machine Learning},line={5},month=sep,number={10},open_access={Gold},publisher={Springer Science and Business Media LLC},title={SafeGen: safeguarding privacy and fairness through a genetic method},visible_on_website={YES},volume={114},year={2025}}