Case studies
4
LINE
In recent years, the development of AI systems focused on uncovering black-box systems through a wide range of explainability methods to make users more aware of why the AI gives the suggestion.
The scientific community's interest on eXplainable Artificial Intelligence (XAI) has produced a multitude of research on computational methods to make explainability possible. Nevertheless, the attention on the final user has been studied with less effort.This line address two main aspects:
- the user’s decision-making process with the eXplainable AI systems used to support high stakes decision;
- use cases to test explanation methods developed in XAI project.
In our first work, we tested the impact of AI explanation with healthcare professionals. Specifically, the context of this work is AI-supported decision-making for clinicians. Imagine, for example, a doctor who wants to have a second opinion before making a decision about the risk of a patient’s myocardial infarction. She forms her opinion on the previous visits and symptoms of the patient and then an AI suggestion is presented to her. What happens to her when she gets a second opinion? Does she trust herself or she will be more prone to follow the algorithmic suggestion to make her final decision? To answer this question, we collected data from 36 healthcare professionals to understand the impact of advice from a clinical DSS in two different cases: the case in which the clinical DSS explains the given suggestion and the case in which it does not. We adapted the judge-advisor system framework from Sniezek & Van Swol [Sniezek2001] to evaluate participants’ trust and behavioral intention to use the system in an online estimation task. Our main measure was the Weight of Advice, a measure of the degree to which the algorithmic suggestion (with or without explanation) influences the participant’s estimate. To have more meaningful insights from the participants, we collected qualitative and quantitative measures. Our results showed that participants relied more on the condition with the explanation compared to the condition with the sole suggestion. This happened even if participants found the explanation unsatisfying. It is interesting to notice that, despite the low perceived explanation quality, participants were influenced by it and relied more on the advice of the AI system. This finding might be in line with previous research on automation bias in medicine, i.e., the tendency to over-rely on automation. From the open questions at the end of the study, healthcare professionals showed an aversion to the use of algorithmic advice and a fear of being replaced by such AI systems. The importance of these results is twofold. Firstly, even if the explanation provided left most of the participants unsatisfied, they were strongly influenced by it and relied more on the advice given by the AI with the suggestion. Secondly, the importance of the ethnographic method, i.e., the open-ended questions, to get more insights from the participants that cannot be caught only with quantitative measures.
The limitations of this study need to be found in the presentation of a decision from the AI that was always correct. In future work, we aim to carry out a similar study testing if the overreliance is still maintained even when the suggestions are wrong. In the second work we performed, we tested how users react to a wrong suggestion when they have to evaluate different types of skin lesions images. The need is to develop AI systems that can assist doctors in making more informed decisions, complementing their own knowledge with the information and suggestion yielded by the AI system [MGY2021, PPP2020]. However, if the logic for the decisions of AI systems is not available it would be impossible to accomplish this goal. Skin image classification is a typical example of this problem. Here, the explanation is formed by synthetic exemplars and counter-exemplars of skin lesions (i.e. images generated and classified with the same outcome as the initial dataset, and with an outcome other than the original dataset, correspondingly). This explanation offers the practitioner a way to highlight the crucial traits responsible for the algorithmic classification decision We conducted a validation survey with 156 domain experts, novices, and laypeople to test whether the explanation increases the reliance and the confidence in the automatic decision system. The task was organized into ten questions. Each of those questions was presented as an image of a skin lesion without any label and its explanation was generated by ABELE. The participants were shown with two exemplars, classified as the presented skin lesion, and two counter-exemplars, i.e. another lesion class. They had to classify the presented image in a binary decision task to decide whether the class of the nevus by using the presented explanation. Here, one of the main points was to see how participants regain their trust after receiving a misclassified suggestion by the AI system. The results showed a slight reduction of trust towards the black box when the presented suggestion is wrong, although there is no statistically significant drop in confidence after receiving wrong advice from an AI model. However, if we restrict our analysis to the sub-sample of medical experts, we have noticed that they are more prone to lower their confidence in the system’s advice even in the subsequent trials compared to the other participants (beginners and laypeople). This study showed how domain experts are more prone to detect and adjust their estimates when the suggestion is not correct. This aspect can be important for the role of the final users of the system. That is to say, explanation methods without a consistent validation can be not taken into account as expected by the developers of such methods. Healthcare is one of the main areas in which we have put our effort to include real participants to get an insight into the effect of AI explanations during the use of clinical assisted decision-making systems. We are focusing on how to improve the explanations in the diagnosis forecasts to inform the design of healthcare systems to promote human-AI cooperation, avoid algorithm aversion and improve the overall decision-making process.
Publications
2.
[GMG2019]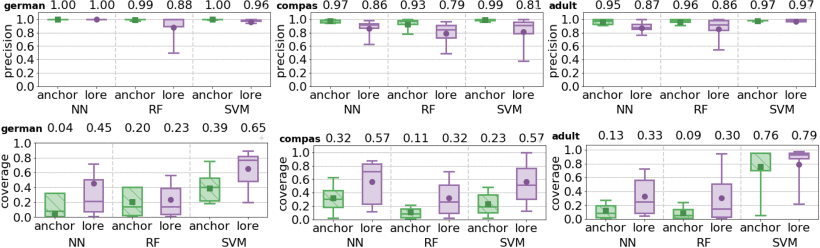
Guidotti Riccardo, Monreale Anna, Giannotti Fosca, Pedreschi Dino, Ruggieri Salvatore, Turini Franco (2021) - IEEE Intelligent Systems. In IEEE Intelligent Systems
Abstract
The rise of sophisticated machine learning models has brought accurate but obscure decision systems, which hide their logic, thus undermining transparency, trust, and the adoption of artificial intelligence (AI) in socially sensitive and safety-critical contexts. We introduce a local rule-based explanation method, providing faithful explanations of the decision made by a black box classifier on a specific instance. The proposed method first learns an interpretable, local classifier on a synthetic neighborhood of the instance under investigation, generated by a genetic algorithm. Then, it derives from the interpretable classifier an explanation consisting of a decision rule, explaining the factual reasons of the decision, and a set of counterfactuals, suggesting the changes in the instance features that would lead to a different outcome. Experimental results show that the proposed method outperforms existing approaches in terms of the quality of the explanations and of the accuracy in mimicking the black box.
3.
[SGM2021]
Setzu Mattia, Guidotti Riccardo, Monreale Anna, Turini Franco, Pedreschi Dino, Giannotti Fosca (2021) - Artificial Intelligence. In Artificial Intelligence
Abstract
Artificial Intelligence (AI) has come to prominence as one of the major components of our society, with applications in most aspects of our lives. In this field, complex and highly nonlinear machine learning models such as ensemble models, deep neural networks, and Support Vector Machines have consistently shown remarkable accuracy in solving complex tasks. Although accurate, AI models often are “black boxes” which we are not able to understand. Relying on these models has a multifaceted impact and raises significant concerns about their transparency. Applications in sensitive and critical domains are a strong motivational factor in trying to understand the behavior of black boxes. We propose to address this issue by providing an interpretable layer on top of black box models by aggregating “local” explanations. We present GLocalX, a “local-first” model agnostic explanation method. Starting from local explanations expressed in form of local decision rules, GLocalX iteratively generalizes them into global explanations by hierarchically aggregating them. Our goal is to learn accurate yet simple interpretable models to emulate the given black box, and, if possible, replace it entirely. We validate GLocalX in a set of experiments in standard and constrained settings with limited or no access to either data or local explanations. Experiments show that GLocalX is able to accurately emulate several models with simple and small models, reaching state-of-the-art performance against natively global solutions. Our findings show how it is often possible to achieve a high level of both accuracy and comprehensibility of classification models, even in complex domains with high-dimensional data, without necessarily trading one property for the other. This is a key requirement for a trustworthy AI, necessary for adoption in high-stakes decision making applications.
18.
[FGP2022]Fedele Andrea, Guidotti Riccardo, Pedreschi Dino (2022) - International Conference on Discovery Science. In Discovery Science
Abstract
Machine learning models are not able to generalize correctly when queried on samples belonging to class distributions that were never seen during training. This is a critical issue, since real world applications might need to quickly adapt without the necessity of re-training. To overcome these limitations, few-shot learning frameworks have been proposed and their applicability has been studied widely for computer vision tasks. Siamese Networks learn pairs similarity in form of a metric that can be easily extended on new unseen classes. Unfortunately, the downside of such systems is the lack of explainability. We propose a method to explain the outcomes of Siamese Networks in the context of few-shot learning for audio data. This objective is pursued through a local perturbation-based approach that evaluates segments-weighted-average contributions to the final outcome considering the interplay between different areas of the audio spectrogram. Qualitative and quantitative results demonstrate that our method is able to show common intra-class characteristics and erroneous reliance on silent sections.
19.
[SGN2022]Spinnato Francesco, Guidotti Riccardo, Nanni Mirco, Maccagnola Daniele, Paciello Giulia, Bencini Farina Antonio (2022) - International Conference on Discovery Science. In Discovery Science
Abstract
In Assicurazioni Generali, an automatic decision-making model is used to check real-time multivariate time series and alert if a car crash happened. In such a way, a Generali operator can call the customer to provide first assistance. The high sensitivity of the model used, combined with the fact that the model is not interpretable, might cause the operator to call customers even though a car crash did not happen but only due to a harsh deviation or the fact that the road is bumpy. Our goal is to tackle the problem of interpretability for car crash prediction and propose an eXplainable Artificial Intelligence (XAI) workflow that allows gaining insights regarding the logic behind the deep learning predictive model adopted by Generali. We reach our goal by building an interpretable alternative to the current obscure model that also reduces the training data usage and the prediction time.
27.
[PBF2022]Panigutti Cecilia, Beretta Andrea, Fadda Daniele , Giannotti Fosca, Pedreschi Dino, Perotti Alan, Rinzivillo Salvatore (2022). In ACM Transactions on Interactive Intelligent Systems
Abstract
eXplainable AI (XAI) involves two intertwined but separate challenges: the development of techniques to extract explanations from black-box AI models, and the way such explanations are presented to users, i.e., the explanation user interface. Despite its importance, the second aspect has received limited attention so far in the literature. Effective AI explanation interfaces are fundamental for allowing human decision-makers to take advantage and oversee high-risk AI systems effectively. Following an iterative design approach, we present the first cycle of prototyping-testing-redesigning of an explainable AI technique, and its explanation user interface for clinical Decision Support Systems (DSS). We first present an XAI technique that meets the technical requirements of the healthcare domain: sequential, ontology-linked patient data, and multi-label classification tasks. We demonstrate its applicability to explain a clinical DSS, and we design a first prototype of an explanation user interface. Next, we test such a prototype with healthcare providers and collect their feedback, with a two-fold outcome: first, we obtain evidence that explanations increase users' trust in the XAI system, and second, we obtain useful insights on the perceived deficiencies of their interaction with the system, so that we can re-design a better, more human-centered explanation interface.
Research Line 1▪3▪4
28.
[PBP2022]Panigutti Cecilia, Beretta Andrea, Pedreschi Dino, Giannotti Fosca (2022) - 2022 Conference on Human Factors in Computing Systems. In Proceedings of the 2022 Conference on Human Factors in Computing Systems
Abstract
The field of eXplainable Artificial Intelligence (XAI) focuses on providing explanations for AI systems' decisions. XAI applications to AI-based Clinical Decision Support Systems (DSS) should increase trust in the DSS by allowing clinicians to investigate the reasons behind its suggestions. In this paper, we present the results of a user study on the impact of advice from a clinical DSS on healthcare providers' judgment in two different cases: the case where the clinical DSS explains its suggestion and the case it does not. We examined the weight of advice, the behavioral intention to use the system, and the perceptions with quantitative and qualitative measures. Our results indicate a more significant impact of advice when an explanation for the DSS decision is provided. Additionally, through the open-ended questions, we provide some insights on how to improve the explanations in the diagnosis forecasts for healthcare assistants, nurses, and doctors.
Research Line 4
30.
[VMG2022]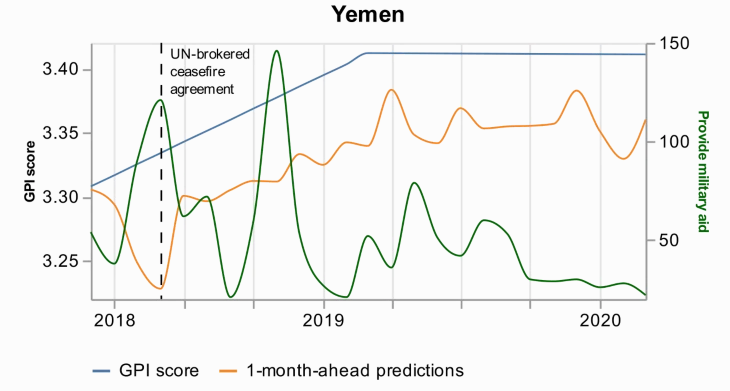
Voukelatou Vasiliki, Miliou Ioanna, Giannotti Fosca, Pappalardo Luca (2022) - EPJ Data Science. In EPJ Data Science
Abstract
Peace is a principal dimension of well-being and is the way out of inequity and violence. Thus, its measurement has drawn the attention of researchers, policymakers, and peacekeepers. During the last years, novel digital data streams have drastically changed the research in this field. The current study exploits information extracted from a new digital database called Global Data on Events, Location, and Tone (GDELT) to capture peace through the Global Peace Index (GPI). Applying predictive machine learning models, we demonstrate that news media attention from GDELT can be used as a proxy for measuring GPI at a monthly level. Additionally, we use explainable AI techniques to obtain the most important variables that drive the predictions. This analysis highlights each country’s profile and provides explanations for the predictions, and particularly for the errors and the events that drive these errors. We believe that digital data exploited by researchers, policymakers, and peacekeepers, with data science tools as powerful as machine learning, could contribute to maximizing the societal benefits and minimizing the risks to peace.
32.
[PMC2022]
Panigutti Cecilia, Monreale Anna, Comandè Giovanni, Pedreschi Dino (2022) - Deep Learning in Biology and Medicine. In Deep Learning in Biology and Medicine
Abstract
Biology, medicine and biochemistry have become data-centric fields for which Deep Learning methods are delivering groundbreaking results. Addressing high impact challenges, Deep Learning in Biology and Medicine provides an accessible and organic collection of Deep Learning essays on bioinformatics and medicine. It caters for a wide readership, ranging from machine learning practitioners and data scientists seeking methodological knowledge to address biomedical applications, to life science specialists in search of a gentle reference for advanced data analytics.With contributions from internationally renowned experts, the book covers foundational methodologies in a wide spectrum of life sciences applications, including electronic health record processing, diagnostic imaging, text processing, as well as omics-data processing. This survey of consolidated problems is complemented by a selection of advanced applications, including cheminformatics and biomedical interaction network analysis. A modern and mindful approach to the use of data-driven methodologies in the life sciences also requires careful consideration of the associated societal, ethical, legal and transparency challenges, which are covered in the concluding chapters of this book.
41.
[MBG2021]Metta Carlo, Beretta Andrea, Guidotti Riccardo, Yin Yuan, Gallinari Patrick, Rinzivillo Salvatore, Giannotti Fosca (2021) - Arxive preprint. In International Journal of Data Science and Analytics
Abstract
A key issue in critical contexts such as medical diagnosis is the interpretability of the deep learning models adopted in decision-making systems. Research in eXplainable Artificial Intelligence (XAI) is trying to solve this issue. However, often XAI approaches are only tested on generalist classifier and do not represent realistic problems such as those of medical diagnosis. In this paper, we analyze a case study on skin lesion images where we customize an existing XAI approach for explaining a deep learning model able to recognize different types of skin lesions. The explanation is formed by synthetic exemplar and counter-exemplar images of skin lesion and offers the practitioner a way to highlight the crucial traits responsible for the classification decision. A survey conducted with domain experts, beginners and unskilled people proof that the usage of explanations increases the trust and confidence in the automatic decision system. Also, an analysis of the latent space adopted by the explainer unveils that some of the most frequent skin lesion classes are distinctly separated. This phenomenon could derive from the intrinsic characteristics of each class and, hopefully, can provide support in the resolution of the most frequent misclassifications by human experts.
43.
[RAB2021]Resta Michele, Monreale Anna, Bacciu Davide (2021) - Entropy. In Entropy
Abstract
The biomedical field is characterized by an ever-increasing production of sequential data, which often come in the form of biosignals capturing the time-evolution of physiological processes, such as blood pressure and brain activity. This has motivated a large body of research dealing with the development of machine learning techniques for the predictive analysis of such biosignals. Unfortunately, in high-stakes decision making, such as clinical diagnosis, the opacity of machine learning models becomes a crucial aspect to be addressed in order to increase the trust and adoption of AI technology. In this paper, we propose a model agnostic explanation method, based on occlusion, that enables the learning of the input’s influence on the model predictions. We specifically target problems involving the predictive analysis of time-series data and the models that are typically used to deal with data of such nature, i.e., recurrent neural networks. Our approach is able to provide two different kinds of explanations: one suitable for technical experts, who need to verify the quality and correctness of machine learning models, and one suited to physicians, who need to understand the rationale underlying the prediction to make aware decisions. A wide experimentation on different physiological data demonstrates the effectiveness of our approach both in classification and regression tasks.
45.
[PPB2021]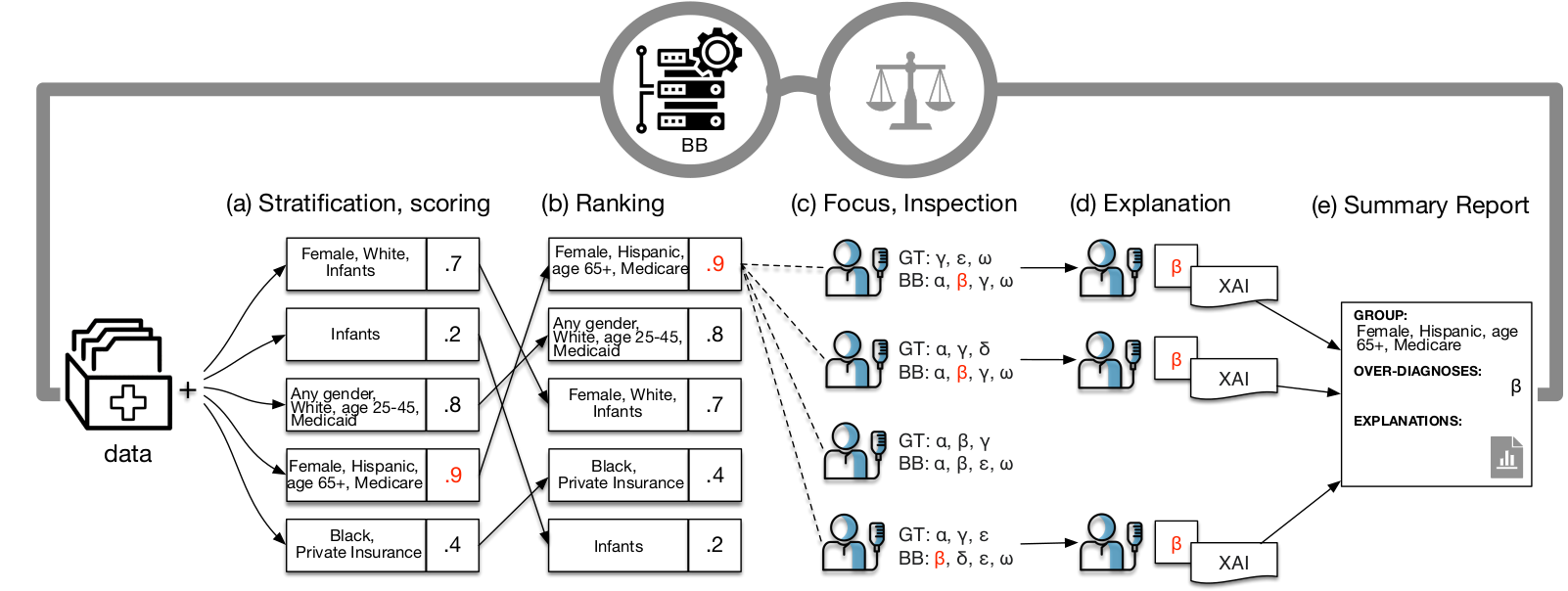
Panigutti Cecilia, Perotti Alan, Panisson André, Bajardi Paolo, Pedreschi Dino (2021) - Information Processing & Management. In Journal of Information Processing and Management
Abstract
Highlights: We present a pipeline to detect and explain potential fairness issues in Clinical DSS. We study and compare different multi-label classification disparity measures. We explore ICD9 bias in MIMIC-IV, an openly available ICU benchmark dataset
46.
[NPN2020]Naretto Francesca, Pellungrini Roberto, Nardini Franco Maria, Giannotti Fosca (2021) - ECML PKDD 2020 Workshops. In ECML PKDD 2020 Workshops
Abstract
The analysis of privacy risk for mobility data is a fundamental part of any privacy-aware process based on such data. Mobility data are highly sensitive. Therefore, the correct identification of the privacy risk before releasing the data to the public is of utmost importance. However, existing privacy risk assessment frameworks have high computational complexity. To tackle these issues, some recent work proposed a solution based on classification approaches to predict privacy risk using mobility features extracted from the data. In this paper, we propose an improvement of this approach by applying long short-term memory (LSTM) neural networks to predict the privacy risk directly from original mobility data. We empirically evaluate privacy risk on real data by applying our LSTM-based approach. Results show that our proposed method based on a LSTM network is effective in predicting the privacy risk with results in terms of F1 of up to 0.91. Moreover, to explain the predictions of our model, we employ a state-of-the-art explanation algorithm, Shap. We explore the resulting explanation, showing how it is possible to provide effective predictions while explaining them to the end-user.
47.
[NPM2020]Naretto Francesca, Pellungrini Roberto, Monreale Anna, Nardini Franco Maria, Musolesi Mirco (2021) - Discovery Science. In Discovery Science Conference
Abstract
Mobility data is a proxy of different social dynamics and its analysis enables a wide range of user services. Unfortunately, mobility data are very sensitive because the sharing of people’s whereabouts may arise serious privacy concerns. Existing frameworks for privacy risk assessment provide tools to identify and measure privacy risks, but they often (i) have high computational complexity; and (ii) are not able to provide users with a justification of the reported risks. In this paper, we propose expert, a new framework for the prediction and explanation of privacy risk on mobility data. We empirically evaluate privacy risk on real data, simulating a privacy attack with a state-of-the-art privacy risk assessment framework. We then extract individual mobility profiles from the data for predicting their risk. We compare the performance of several machine learning algorithms in order to identify the best approach for our task. Finally, we show how it is possible to explain privacy risk prediction on real data, using two algorithms: Shap, a feature importance-based method and Lore, a rule-based method. Overall, expert is able to provide a user with the privacy risk and an explanation of the risk itself. The experiments show excellent performance for the prediction task.
54.
[PGM2019]
Panigutti Cecilia, Guidotti Riccardo, Monreale Anna, Pedreschi Dino (2021) - Precision Health and Medicine. In International Workshop on Health Intelligence (pp. 97-110). Springer, Cham.
Abstract
Today the state-of-the-art performance in classification is achieved by the so-called “black boxes”, i.e. decision-making systems whose internal logic is obscure. Such models could revolutionize the health-care system, however their deployment in real-world diagnosis decision support systems is subject to several risks and limitations due to the lack of transparency. The typical classification problem in health-care requires a multi-label approach since the possible labels are not mutually exclusive, e.g. diagnoses. We propose MARLENA, a model-agnostic method which explains multi-label black box decisions. MARLENA explains an individual decision in three steps. First, it generates a synthetic neighborhood around the instance to be explained using a strategy suitable for multi-label decisions. It then learns a decision tree on such neighborhood and finally derives from it a decision rule that explains the black box decision. Our experiments show that MARLENA performs well in terms of mimicking the black box behavior while gaining at the same time a notable amount of interpretability through compact decision rules, i.e. rules with limited length.
57.
[PPP2020]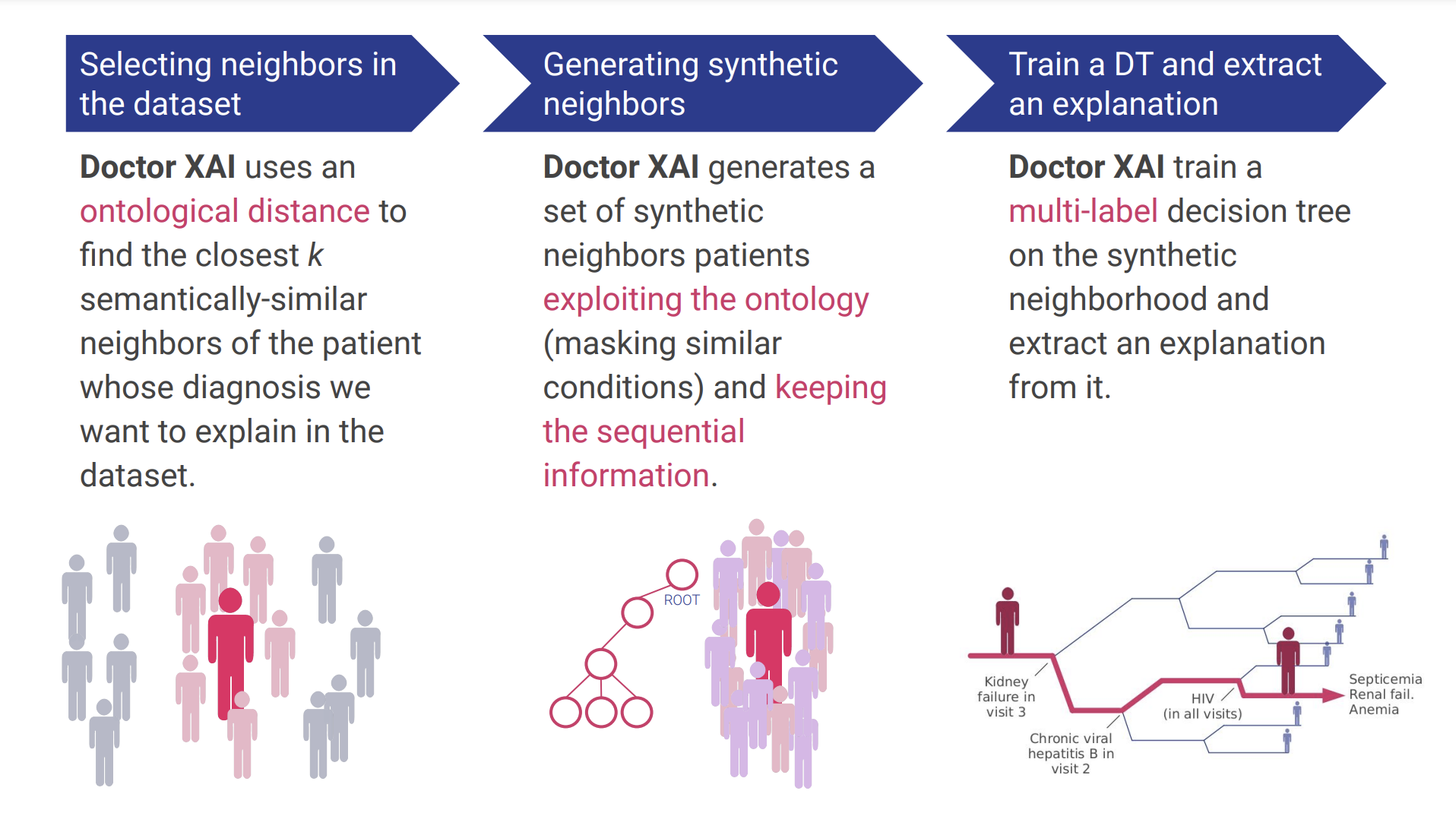
Panigutti Cecilia, Perotti Alan, Pedreschi Dino (2020) - FAT* '20: Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency. In FAT* '20: Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency
Abstract
Several recent advancements in Machine Learning involve blackbox models: algorithms that do not provide human-understandable explanations in support of their decisions. This limitation hampers the fairness, accountability and transparency of these models; the field of eXplainable Artificial Intelligence (XAI) tries to solve this problem providing human-understandable explanations for black-box models. However, healthcare datasets (and the related learning tasks) often present peculiar features, such as sequential data, multi-label predictions, and links to structured background knowledge. In this paper, we introduce Doctor XAI, a model-agnostic explainability technique able to deal with multi-labeled, sequential, ontology-linked data. We focus on explaining Doctor AI, a multilabel classifier which takes as input the clinical history of a patient in order to predict the next visit. Furthermore, we show how exploiting the temporal dimension in the data and the domain knowledge encoded in the medical ontology improves the quality of the mined explanations.
62.
[GPP2019]
Giannotti Fosca, Pedreschi Dino, Panigutti Cecilia (2019) - Biopolitica, Pandemia e democrazia. Rule of law nella società digitale. In BIOPOLITICA, PANDEMIA E DEMOCRAZIA Rule of law nella società digitale
Abstract
La crisi sanitaria ha trasformato le relazioni tra Stato e cittadini, conducendo a limitazioni temporanee dei diritti fondamentali e facendo emergere conflitti tra le due dimensioni della salute, come diritto della persona e come diritto della comunità, e tra il diritto alla salute e le esigenze del sistema economico. Per far fronte all’emergenza, si è modificato il tradizionale equilibrio tra i poteri dello Stato, in una prospettiva in cui il tempo dell’emergenza sembra proiettarsi ancora a lungo sul futuro. La pandemia ha inoltre potenziato la centralità del digitale, dall’utilizzo di software di intelligenza artificiale per il tracciamento del contagio alla nuova connettività del lavoro remoto, passando per la telemedicina. Le nuove tecnologie svolgono un ruolo di prevenzione e controllo, ma pongono anche delicate questioni costituzionali: come tutelare la privacy individuale di fronte al Panopticon digitale? Come inquadrare lo statuto delle piattaforme digitali, veri e propri poteri tecnologici privati, all’interno dei nostri ordinamenti? La ricerca presentata in questo volume e nei due volumi collegati propone le riflessioni su questi temi di studiosi afferenti a una moltitudine di aree disciplinari: medici, giuristi, ingegneri, esperti di robotica e di IA analizzano gli effetti dell’emergenza sanitaria sulla tenuta del modello democratico occidentale, con l’obiettivo di aprire una riflessione sulle linee guida per la ricostruzione del Paese, oltre la pandemia. In particolare, questo terzo volume affronta gli aspetti legati all’impatto della tecnologia digitale e dell’IA sui processi, sulla scuola e sulla medicina, con una riflessione su temi quali l’organizzazione della giustizia, le responsabilità, le carenze organizzative degli enti.
Researchers working on this line

Riccardo
Guidotti
University of Pisa
R. line 1 ▪ 3 ▪ 4 ▪ 5

Mirco
Nanni
ISTI - CNR Pisa
R. line 1 ▪ 4

Luca
Pappalardo
ISTI - CNR Pisa
R. line 4

Salvo
Rinzivillo
ISTI - CNR Pisa
R. line 1 ▪ 3 ▪ 4 ▪ 5

Andrea
Beretta
ISTI - CNR Pisa
R. line 1 ▪ 4 ▪ 5

Anna
Monreale
University of Pisa
R. line 1 ▪ 4 ▪ 5

Cecilia
Panigutti
Scuola Normale
R. line 1 ▪ 4 ▪ 5

Francesco
Spinnato
Scuola Normale
R. line 1 ▪ 4

Francesca
Naretto
Scuola Normale
R. line 1 ▪ 3 ▪ 4 ▪ 5

Carlo
Metta
ISTI - CNR Pisa
R. line 1 ▪ 2 ▪ 3 ▪4

Eleonora
Cappuccio
University of Pisa - Bari
R. line 3 ▪ 4

Alessio
Malizia
University of Pisa
R. line 1 ▪ 3 ▪ 4

Samuele
Tonati
University of Pisa
R. line 4

Federico
Mazzoni
University of Pisa
R. line 1 ▪ 4

Leticia
Decker deSousa
Scuola Normale
R. line 4

Gizem
Gezici
Scuola Normale
R. line 4