Anna Monreale

Research Line 5 - leader
Involved in the research line 1 ▪ 4 ▪ 5
Role: Associate Professor
Affiliation: University of Pisa
1.
[GMR2018]Guidotti Riccardo, Monreale Anna, Ruggieri Salvatore, Turini Franco, Giannotti Fosca, Pedreschi Dino (2022) - ACM Computing Surveys. In ACM computing surveys (CSUR), 51(5), 1-42.
Abstract
In recent years, many accurate decision support systems have been constructed as black boxes, that is as systems that hide their internal logic to the user. This lack of explanation constitutes both a practical and an ethical issue. The literature reports many approaches aimed at overcoming this crucial weakness, sometimes at the cost of sacrificing accuracy for interpretability. The applications in which black box decision systems can be used are various, and each approach is typically developed to provide a solution for a specific problem and, as a consequence, it explicitly or implicitly delineates its own definition of interpretability and explanation. The aim of this article is to provide a classification of the main problems addressed in the literature with respect to the notion of explanation and the type of black box system. Given a problem definition, a black box type, and a desired explanation, this survey should help the researcher to find the proposals more useful for his own work. The proposed classification of approaches to open black box models should also be useful for putting the many research open questions in perspective.
2.
[GMG2019]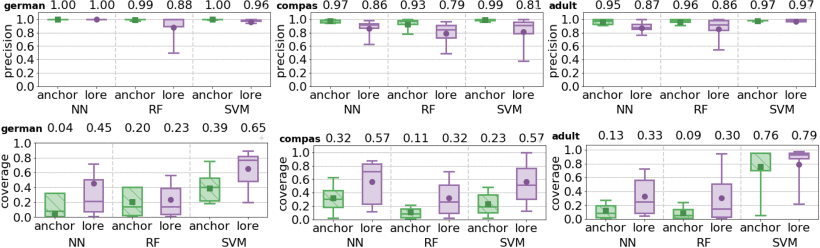
Guidotti Riccardo, Monreale Anna, Giannotti Fosca, Pedreschi Dino, Ruggieri Salvatore, Turini Franco (2021) - IEEE Intelligent Systems. In IEEE Intelligent Systems
Abstract
The rise of sophisticated machine learning models has brought accurate but obscure decision systems, which hide their logic, thus undermining transparency, trust, and the adoption of artificial intelligence (AI) in socially sensitive and safety-critical contexts. We introduce a local rule-based explanation method, providing faithful explanations of the decision made by a black box classifier on a specific instance. The proposed method first learns an interpretable, local classifier on a synthetic neighborhood of the instance under investigation, generated by a genetic algorithm. Then, it derives from the interpretable classifier an explanation consisting of a decision rule, explaining the factual reasons of the decision, and a set of counterfactuals, suggesting the changes in the instance features that would lead to a different outcome. Experimental results show that the proposed method outperforms existing approaches in terms of the quality of the explanations and of the accuracy in mimicking the black box.
3.
[SGM2021]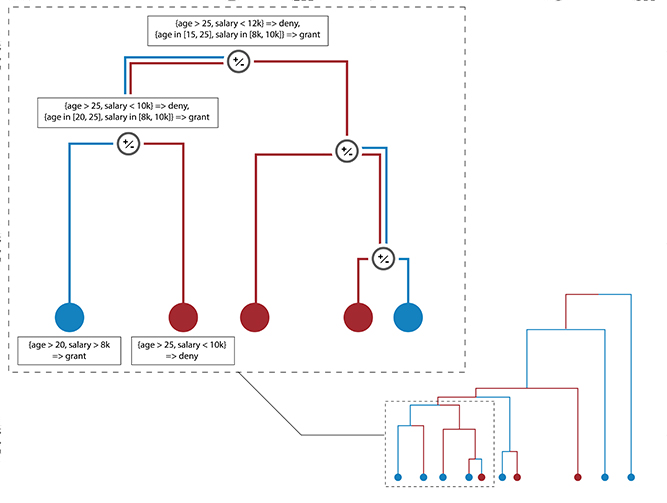
Setzu Mattia, Guidotti Riccardo, Monreale Anna, Turini Franco, Pedreschi Dino, Giannotti Fosca (2021) - Artificial Intelligence. In Artificial Intelligence
Abstract
Artificial Intelligence (AI) has come to prominence as one of the major components of our society, with applications in most aspects of our lives. In this field, complex and highly nonlinear machine learning models such as ensemble models, deep neural networks, and Support Vector Machines have consistently shown remarkable accuracy in solving complex tasks. Although accurate, AI models often are “black boxes” which we are not able to understand. Relying on these models has a multifaceted impact and raises significant concerns about their transparency. Applications in sensitive and critical domains are a strong motivational factor in trying to understand the behavior of black boxes. We propose to address this issue by providing an interpretable layer on top of black box models by aggregating “local” explanations. We present GLocalX, a “local-first” model agnostic explanation method. Starting from local explanations expressed in form of local decision rules, GLocalX iteratively generalizes them into global explanations by hierarchically aggregating them. Our goal is to learn accurate yet simple interpretable models to emulate the given black box, and, if possible, replace it entirely. We validate GLocalX in a set of experiments in standard and constrained settings with limited or no access to either data or local explanations. Experiments show that GLocalX is able to accurately emulate several models with simple and small models, reaching state-of-the-art performance against natively global solutions. Our findings show how it is often possible to achieve a high level of both accuracy and comprehensibility of classification models, even in complex domains with high-dimensional data, without necessarily trading one property for the other. This is a key requirement for a trustworthy AI, necessary for adoption in high-stakes decision making applications.
4.
[GMR2018a]Guidotti Riccardo, Monreale Anna, Ruggieri Salvatore , Pedreschi Dino, Turini Franco , Giannotti Fosca (2018) - Arxive preprint
Abstract
The recent years have witnessed the rise of accurate but obscure decision systems which hide the logic of their internal decision processes to the users. The lack of explanations for the decisions of black box systems is a key ethical issue, and a limitation to the adoption of achine learning components in socially sensitive and safety-critical contexts. Therefore, we need explanations that reveals the reasons why a predictor takes a certain decision. In this paper we focus on the problem of black box outcome explanation, i.e., explaining the reasons of the decision taken on a specific instance. We propose LORE, an agnostic method able to provide interpretable and faithful explanations. LORE first leans a local interpretable predictor on a synthetic neighborhood generated by a genetic algorithm. Then it derives from the logic of the local interpretable predictor a meaningful explanation consisting of: a decision rule, which explains the reasons of the decision; and a set of counterfactual rules, suggesting the changes in the instance's features that lead to a different outcome. Wide experiments show that LORE outperforms existing methods and baselines both in the quality of explanations and in the accuracy in mimicking the black box.
6.
[SGM2023]Francesco Spinnato, Riccardo Guidotti, Anna Monreale, Mirco Nanni, Dino Pedreschi, Fosca Giannotti (2023) - ACM Transactions on Knowledge Discovery from Data
Abstract
The growing availability of time series data has increased the usage of classifiers for this data type. Unfortunately, state-of-the-art time series classifiers are black-box models and, therefore, not usable in critical domains such as healthcare or finance, where explainability can be a crucial requirement. This paper presents a framework to explain the predictions of any black-box classifier for univariate and multivariate time series. The provided explanation is composed of three parts. First, a saliency map highlighting the most important parts of the time series for the classification. Second, an instance-based explanation exemplifies the black-box’s decision by providing a set of prototypical and counterfactual time series. Third, a factual and counterfactual rule-based explanation, revealing the reasons for the classification through logical conditions based on subsequences that must, or must not, be contained in the time series. Experiments and benchmarks show that the proposed method provides faithful, meaningful, stable, and interpretable explanations.
12.
[LSG2023]Landi Cristiano,Spinnato Francesco, Guidotti Riccardo, Monreale Anna, Nanni Mirco (2023) - International Symposium on Intelligent Data Analysis. In Proceedings of the 2023 conference Advances in Intelligent Data Analysis XXI
Abstract
The large and diverse availability of mobility data enables the development of predictive models capable of recognizing various types of movements. Through a variety of GPS devices, any moving entity, animal, person, or vehicle can generate spatio-temporal trajectories. This data is used to infer migration patterns, manage traffic in large cities, and monitor the spread and impact of diseases, all critical situations that necessitate a thorough understanding of the underlying problem. Researchers, businesses, and governments use mobility data to make decisions that affect people’s lives in many ways, employing accurate but opaque deep learning models that are difficult to interpret from a human standpoint. To address these limitations, we propose Geolet, a human-interpretable machine-learning model for trajectory classification. We use discriminative sub-trajectories extracted from mobility data to turn trajectories into a simplified representation that can be used as input by any machine learning classifier. We test our approach against state-of-the-art competitors on real-world datasets. Geolet outperforms black-box models in terms of accuracy while being orders of magnitude faster than its interpretable competitors.
17.
[NMG2022]Naretto Francesca, Monreale Anna, Giannotti Fosca (2022) - 2022 IEEE 4th International Conference on Cognitive Machine Intelligence (CogMI). In IEEE International Conference on Cognitive Machine Intelligence (CogMI)
Abstract
In recent years we are witnessing the diffusion of AI systems based on powerful Machine Learning models which find application in many critical contexts such as medicine, financial market and credit scoring. In such a context it is particularly important to design Trustworthy AI systems while guaranteeing transparency, with respect to their decision reasoning and privacy protection. Although many works in the literature addressed the lack of transparency and the risk of privacy exposure of Machine Learning models, the privacy risks of explainers have not been appropriately studied. This paper presents a methodology for evaluating the privacy exposure raised by interpretable global explainers able to imitate the original black-box classifier. Our methodology exploits the well-known Membership Inference Attack. The experimental results highlight that global explainers based on interpretable trees lead to an increase in privacy exposure.
20.
[NMG2022]Francesca Naretto, Anna Monreale, Fosca Giannotti (2022) - Proceedings of the First International Conference on Hybrid Human-Artificial Intelligence. In Frontiers in Artificial Intelligence and Applications
Abstract
nan
Research Line 5
29.
[SMM2022]Setzu Mattia, Monreale Anna, Minervini Pasquale (2022) - Third Conference on Cognitive Machine Intelligence (COGMI) 2021
Abstract
nan
Research Line 1▪2
32.
[PMC2022]
Panigutti Cecilia, Monreale Anna, Comandè Giovanni, Pedreschi Dino (2022) - Deep Learning in Biology and Medicine. In Deep Learning in Biology and Medicine
Abstract
Biology, medicine and biochemistry have become data-centric fields for which Deep Learning methods are delivering groundbreaking results. Addressing high impact challenges, Deep Learning in Biology and Medicine provides an accessible and organic collection of Deep Learning essays on bioinformatics and medicine. It caters for a wide readership, ranging from machine learning practitioners and data scientists seeking methodological knowledge to address biomedical applications, to life science specialists in search of a gentle reference for advanced data analytics.With contributions from internationally renowned experts, the book covers foundational methodologies in a wide spectrum of life sciences applications, including electronic health record processing, diagnostic imaging, text processing, as well as omics-data processing. This survey of consolidated problems is complemented by a selection of advanced applications, including cheminformatics and biomedical interaction network analysis. A modern and mindful approach to the use of data-driven methodologies in the life sciences also requires careful consideration of the associated societal, ethical, legal and transparency challenges, which are covered in the concluding chapters of this book.
35.
[GMP2021]
Guidotti Riccardo, Monreale Anna, Pedreschi Dino, Giannotti Fosca (2021) - Explainable AI Within the Digital Transformation and Cyber Physical Systems (pp. 9-31)
Abstract
This book presents Explainable Artificial Intelligence (XAI), which aims at producing explainable models that enable human users to understand and appropriately trust the obtained results. The authors discuss the challenges involved in making machine learning-based AI explainable. Firstly, that the explanations must be adapted to different stakeholders (end-users, policy makers, industries, utilities etc.) with different levels of technical knowledge (managers, engineers, technicians, etc.) in different application domains. Secondly, that it is important to develop an evaluation framework and standards in order to measure the effectiveness of the provided explanations at the human and the technical levels. This book gathers research contributions aiming at the development and/or the use of XAI techniques in order to address the aforementioned challenges in different applications such as healthcare, finance, cybersecurity, and document summarization. It allows highlighting the benefits and requirements of using explainable models in different application domains in order to provide guidance to readers to select the most adapted models to their specified problem and conditions. Includes recent developments of the use of Explainable Artificial Intelligence (XAI) in order to address the challenges of digital transition and cyber-physical systems; Provides a textual scientific description of the use of XAI in order to address the challenges of digital transition and cyber-physical systems; Presents examples and case studies in order to increase transparency and understanding of the methodological concepts.
38.
[GM2021]Guidotti Riccardo, Monreale Anna (2021) - Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society
Abstract
Time series shapelets are discriminatory subsequences which are representative of a class, and their similarity to a time series can be used for successfully tackling the time series classification problem. The literature shows that Artificial Intelligence (AI) systems adopting classification models based on time series shapelets can be interpretable, more accurate, and significantly fast. Thus, in order to design a data-agnostic and interpretable classification approach, in this paper we first extend the notion of shapelets to different types of data, i.e., images, tabular and textual data. Then, based on this extended notion of shapelets we propose an interpretable data-agnostic classification method. Since the shapelets discovery can be time consuming, especially for data types more complex than time series, we exploit a notion of prototypes for finding candidate shapelets, and reducing both the time required to find a solution and the variance of shapelets. A wide experimentation on datasets of different types shows that the data-agnostic prototype-based shapelets returned by the proposed method empower an interpretable classification which is also fast, accurate, and stable. In addition, we show and we prove that shapelets can be at the basis of explainable AI methods.
42.
[BGM2021]Bonsignori Valerio, Guidotti Riccardo, Monreale Anna (2021) - Discovery Science
Abstract
Decision tree classifiers have been proved to be among the most interpretable models due to their intuitive structure that illustrates decision processes in form of logical rules. Unfortunately, more complex tree-based classifiers such as oblique trees and random forests overcome the accuracy of decision trees at the cost of becoming non interpretable. In this paper, we propose a method that takes as input any tree-based classifier and returns a single decision tree able to approximate its behavior. Our proposal merges tree-based classifiers by an intensional and extensional approach and applies a post-hoc explanation strategy. Our experiments shows that the retrieved single decision tree is at least as accurate as the original tree-based model, faithful, and more interpretable.
43.
[RAB2021]Resta Michele, Monreale Anna, Bacciu Davide (2021) - Entropy. In Entropy
Abstract
The biomedical field is characterized by an ever-increasing production of sequential data, which often come in the form of biosignals capturing the time-evolution of physiological processes, such as blood pressure and brain activity. This has motivated a large body of research dealing with the development of machine learning techniques for the predictive analysis of such biosignals. Unfortunately, in high-stakes decision making, such as clinical diagnosis, the opacity of machine learning models becomes a crucial aspect to be addressed in order to increase the trust and adoption of AI technology. In this paper, we propose a model agnostic explanation method, based on occlusion, that enables the learning of the input’s influence on the model predictions. We specifically target problems involving the predictive analysis of time-series data and the models that are typically used to deal with data of such nature, i.e., recurrent neural networks. Our approach is able to provide two different kinds of explanations: one suitable for technical experts, who need to verify the quality and correctness of machine learning models, and one suited to physicians, who need to understand the rationale underlying the prediction to make aware decisions. A wide experimentation on different physiological data demonstrates the effectiveness of our approach both in classification and regression tasks.
47.
[NPM2020]Naretto Francesca, Pellungrini Roberto, Monreale Anna, Nardini Franco Maria, Musolesi Mirco (2021) - Discovery Science. In Discovery Science Conference
Abstract
Mobility data is a proxy of different social dynamics and its analysis enables a wide range of user services. Unfortunately, mobility data are very sensitive because the sharing of people’s whereabouts may arise serious privacy concerns. Existing frameworks for privacy risk assessment provide tools to identify and measure privacy risks, but they often (i) have high computational complexity; and (ii) are not able to provide users with a justification of the reported risks. In this paper, we propose expert, a new framework for the prediction and explanation of privacy risk on mobility data. We empirically evaluate privacy risk on real data, simulating a privacy attack with a state-of-the-art privacy risk assessment framework. We then extract individual mobility profiles from the data for predicting their risk. We compare the performance of several machine learning algorithms in order to identify the best approach for our task. Finally, we show how it is possible to explain privacy risk prediction on real data, using two algorithms: Shap, a feature importance-based method and Lore, a rule-based method. Overall, expert is able to provide a user with the privacy risk and an explanation of the risk itself. The experiments show excellent performance for the prediction task.
48.
[SGM2019]Setzu Mattia, Guidotti Riccardo, Monreale Anna, Turini Franco (2021) - Machine Learning and Knowledge Discovery in Databases. In ECML PKDD 2019: Machine Learning and Knowledge Discovery in Databases
Abstract
Artificial Intelligence systems often adopt machine learning models encoding complex algorithms with potentially unknown behavior. As the application of these “black box” models grows, it is our responsibility to understand their inner working and formulate them in human-understandable explanations. To this end, we propose a rule-based model-agnostic explanation method that follows a local-to-global schema: it generalizes a global explanation summarizing the decision logic of a black box starting from the local explanations of single predicted instances. We define a scoring system based on a rule relevance score to extract global explanations from a set of local explanations in the form of decision rules. Experiments on several datasets and black boxes show the stability, and low complexity of the global explanations provided by the proposed solution in comparison with baselines and state-of-the-art global explainers.
51.
[PGG2019]Pedreschi Dino, Giannotti Fosca, Guidotti Riccardo, Monreale Anna, Ruggieri Salvatore, Turini Franco (2021) - Proceedings of the AAAI Conference on Artificial Intelligence. In Proceedings of the AAAI Conference on Artificial Intelligence
Abstract
Black box AI systems for automated decision making, often based on machine learning over (big) data, map a user’s features into a class or a score without exposing the reasons why. This is problematic not only for lack of transparency, but also for possible biases inherited by the algorithms from human prejudices and collection artifacts hidden in the training data, which may lead to unfair or wrong decisions. We focus on the urgent open challenge of how to construct meaningful explanations of opaque AI/ML systems, introducing the local-toglobal framework for black box explanation, articulated along three lines: (i) the language for expressing explanations in terms of logic rules, with statistical and causal interpretation; (ii) the inference of local explanations for revealing the decision rationale for a specific case, by auditing the black box in the vicinity of the target instance; (iii), the bottom-up generalization of many local explanations into simple global ones, with algorithms that optimize for quality and comprehensibility. We argue that the local-first approach opens the door to a wide variety of alternative solutions along different dimensions: a variety of data sources (relational, text, images, etc.), a variety of learning problems (multi-label classification, regression, scoring, ranking), a variety of languages for expressing meaningful explanations, a variety of means to audit a black box.
54.
[PGM2019]
Panigutti Cecilia, Guidotti Riccardo, Monreale Anna, Pedreschi Dino (2021) - Precision Health and Medicine. In International Workshop on Health Intelligence (pp. 97-110). Springer, Cham.
Abstract
Today the state-of-the-art performance in classification is achieved by the so-called “black boxes”, i.e. decision-making systems whose internal logic is obscure. Such models could revolutionize the health-care system, however their deployment in real-world diagnosis decision support systems is subject to several risks and limitations due to the lack of transparency. The typical classification problem in health-care requires a multi-label approach since the possible labels are not mutually exclusive, e.g. diagnoses. We propose MARLENA, a model-agnostic method which explains multi-label black box decisions. MARLENA explains an individual decision in three steps. First, it generates a synthetic neighborhood around the instance to be explained using a strategy suitable for multi-label decisions. It then learns a decision tree on such neighborhood and finally derives from it a decision rule that explains the black box decision. Our experiments show that MARLENA performs well in terms of mimicking the black box behavior while gaining at the same time a notable amount of interpretability through compact decision rules, i.e. rules with limited length.
55.
[GMC2019]Guidotti Riccardo, Monreale Anna, Cariaggi Leonardo (2021) - Advances in Knowledge Discovery and Data Mining. In In Pacific-Asia Conference on Knowledge Discovery and Data Mining (pp. 55-68). Springer, Cham.
Abstract
Given the wide use of machine learning approaches based on opaque prediction models, understanding the reasons behind decisions of black box decision systems is nowadays a crucial topic. We address the problem of providing meaningful explanations in the widely-applied image classification tasks. In particular, we explore the impact of changing the neighborhood generation function for a local interpretable model-agnostic explanator by proposing four different variants. All the proposed methods are based on a grid-based segmentation of the images, but each of them proposes a different strategy for generating the neighborhood of the image for which an explanation is required. A deep experimentation shows both improvements and weakness of each proposed approach.
56.
[GMS2020]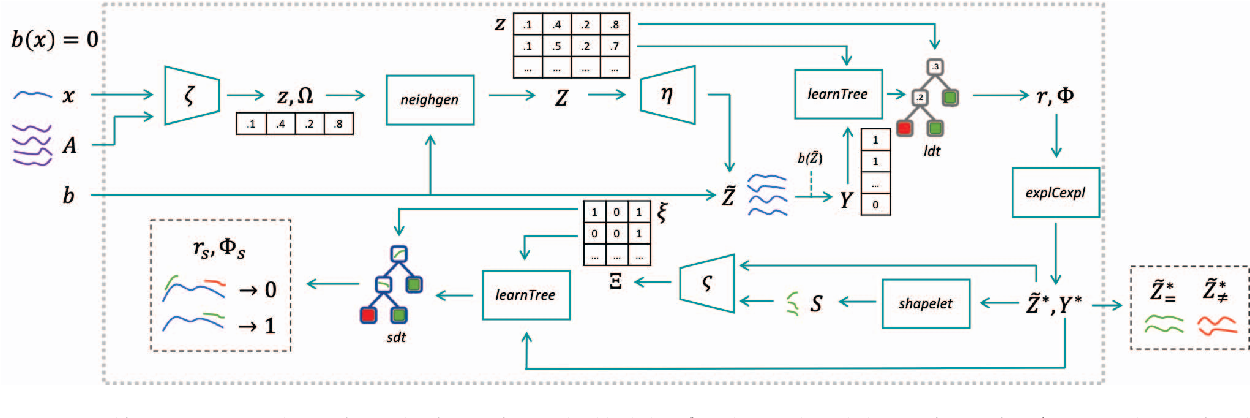
Guidotti Riccardo, Monreale Anna, Spinnato Francesco, Pedreschi Dino, Giannotti Fosca (2020) - 2020 IEEE Second International Conference on Cognitive Machine Intelligence (CogMI)
Abstract
We present a method to explain the decisions of black box models for time series classification. The explanation consists of factual and counterfactual shapelet-based rules revealing the reasons for the classification, and of a set of exemplars and counter-exemplars highlighting similarities and differences with the time series under analysis. The proposed method first generates exemplar and counter-exemplar time series in the latent feature space and learns a local latent decision tree classifier. Then, it selects and decodes those respecting the decision rules explaining the decision. Finally, it learns on them a shapelet-tree that reveals the parts of the time series that must, and must not, be contained for getting the returned outcome from the black box. A wide experimentation shows that the proposed method provides faithful, meaningful and interpretable explanations.
58.
[RGG2020]Ruggieri Salvatore, Giannotti Fosca, Guidotti Riccardo, Monreale Anna, Pedreschi Dino, Turini Franco (2020). In ANNUARIO DI DIRITTO COMPARATO E DI STUDI LEGISLATIVI
Abstract
The pervasive adoption of Artificial Intelligence (AI) models in the modern information society, requires counterbalancing the growing decision power demanded to AI models with risk assessment methodologies. In this paper, we consider the risk of discriminatory decisions and review approaches for discovering discrimination and for designing fair AI models. We highlight the tight relations between discrimination discovery and explainable AI, with the latter being a more general approach for understanding the behavior of black boxes.
59.
[GM2020]Guidotti Riccardo, Monreale Anna (2020) - 2020 IEEE International Conference on Data Mining (ICDM). In 2020 IEEE International Conference on Data Mining (ICDM)
Abstract
Synthetic data generation has been widely adopted in software testing, data privacy, imbalanced learning, machine learning explanation, etc. In such contexts, it is important to generate data samples located within “local” areas surrounding specific instances. Local synthetic data can help the learning phase of predictive models, and it is fundamental for methods explaining the local behavior of obscure classifiers. The contribution of this paper is twofold. First, we introduce a method based on generative operators allowing the synthetic neighborhood generation by applying specific perturbations on a given input instance. The key factor consists in performing a data transformation that makes applicable to any type of data, i.e., data-agnostic. Second, we design a framework for evaluating the goodness of local synthetic neighborhoods exploiting both supervised and unsupervised methodologies. A deep experimentation shows the effectiveness of the proposed method.
61.
[M2020]Monreale Anna (2020) - DPCE Online, [S.l.], v. 44, n. 3. In DPCE Online, [S.l.], v. 44, n. 3, oct. 2020. ISSN 2037-6677
Abstract
nan
Research Line 5
63.
[GMP2019]Guidotti Riccardo, Monreale Anna, Pedreschi Dino (2019) - ERCIM News, 116, 12-13. In ERCIM News, 116, 12-13
Abstract
nan
Research Line 1▪2▪3
64.
[PGG2018]Pedreschi Dino, Giannotti Fosca, Guidotti Riccardo, Monreale Anna , Pappalardo Luca , Ruggieri Salvatore , Turini Franco (2018) - Arxive preprint
Abstract
Black box systems for automated decision making, often based on machine learning over (big) data, map a user's features into a class or a score without exposing the reasons why. This is problematic not only for lack of transparency, but also for possible biases hidden in the algorithms, due to human prejudices and collection artifacts hidden in the training data, which may lead to unfair or wrong decisions. We introduce the local-to-global framework for black box explanation, a novel approach with promising early results, which paves the road for a wide spectrum of future developments along three dimensions: (i) the language for expressing explanations in terms of highly expressive logic-based rules, with a statistical and causal interpretation; (ii) the inference of local explanations aimed at revealing the logic of the decision adopted for a specific instance by querying and auditing the black box in the vicinity of the target instance; (iii), the bottom-up generalization of the many local explanations into simple global ones, with algorithms that optimize the quality and comprehensibility of explanations.