Topics in Selective Prediction
Date: May 24, 2024
Thesis Abstract: With the increasing deployment of Machine Learning (ML) models in many socially-sensitive predictive tasks, there is a growing demand for reliable and trustworthy predictions. For example, the Artificial Intelligence (AI) Act of the European Union rules that ``[h]igh-risk AI systems shall be designed and developed in such a way that they achieve, in the light of their intended purpose, an appropriate level of accuracy [and] robustness’’.
One way to accomplish these requirements is to allow ML models to abstain from making a prediction when there is a high risk of making an error.
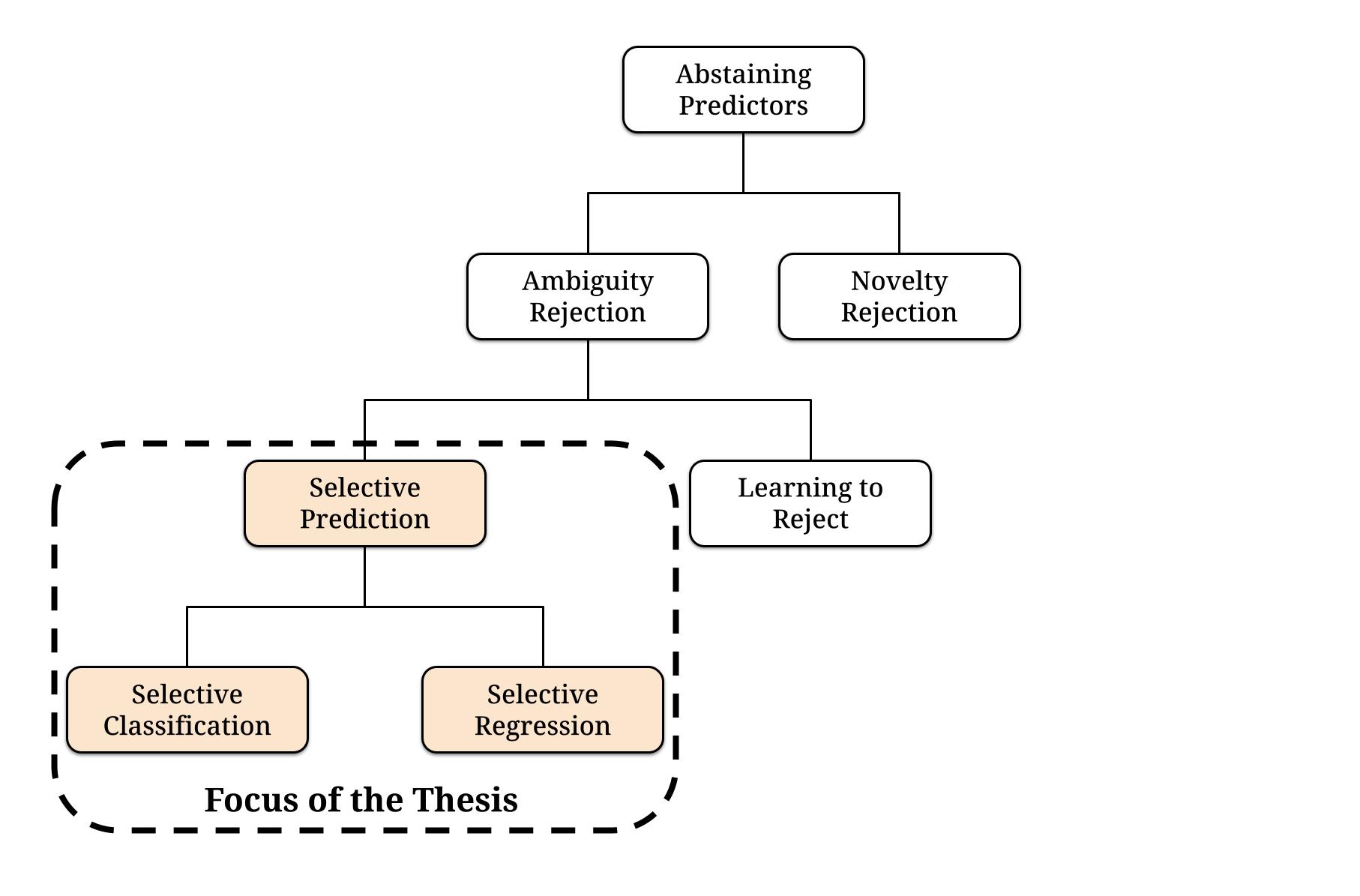
Among the different approaches that build abstaining systems, the selective prediction framework adds a selection mechanism to the ML model, which selects those instances for which the model will provide a prediction. Selective prediction aims at balancing the fraction of abstained instances versus the improvement in predictive performance on the selected ones.
In this thesis, we address three main challenges faced by current approaches in selective prediction.
First, we tackle the limitations of model-specific approaches by proposing model-agnostic heuristics for both the selective classification and the selective regression tasks.
Second, we depart from distributive metric losses (such as accuracy), which are not well-suited in the case of imbalanced classes, by devising an approach to optimize the AUC metrics. The approach is used in a deployed credit scoring system for labelling predicted scores with uncertainty ratings.
Third, we clarify the relative strengths and weaknesses of the state-of-the-art approaches, also including those introduced in this thesis, by an extensive and throughout empirical evaluation.
The effectiveness of the methods proposed in the thesis is supported by theoretical foundations and experimental results.